Mon Résumé Des Concepts Du Big Data

Cet été, j’ai fait un stage dans une jeune startup normande : Creative Data. Un des sujets de mon stage a été de travailler sur les technologies du Big Data, et j’ai donc passé un certain temps à apprendre des choses sur le Big Data. Ce post présente les concepts principaux et quelques avis concernant ce domaine.
Au programme :
- Pourquoi le Big Data ?
- Vers une approche distribuée et « simplifiée »
- Hadoop
- Résumé des technologies Big Data
- Distributions Hadoop
- Evolution du Big Data : le développement de Spark et la fin de MapReduce
- Hadoop dans le cloud
Pourquoi le Big Data ?
Tout d’abord, notons que dans ce post « technologies actuelles » signifie technologies non-Big Data, ce qui n’est bien sur pas vrai.
La problématique à laquelle répond le Big Data est souvent illustrée par la règle des 3V, décrivant trois composantes auxquelles le Big Data doit répondre :
- Volume : Les volumes de données à traiter sont de plus en plus importants et les solutions de traitement actuelles, majoritairement peu scalable ne permettent plus de répondre à une telle augmentation des volumes. Les solutions étant généralement centralisées sur une seule machine, il arrive en effet un moment où l’augmentation des capacités d’une machine n’est plus possible pour des raisons techniques ou des raisons de coût.
- Variété : Les données ne sont plus seulement issues de systèmes structurées (bases relationnelles) mais sont de plus en plus semi-structurées voire non-structurées (données textuelles, images, logs serveurs, etc.), alors que les outils de traitement traditionnels sont souvent prévus pour fonctionner avec des données structurées.
- Vélocité : Les temps de traitement sont parfois cruciaux, et les solutions actuelles peuvent avoir du mal à répondre en un temps suffisant, toujours pour des raisons de non-_scalabilité_.
Les solutions regroupées sous le terme de « Big Data » permettent de répondre efficacement a au moins une voire généralement plusieurs de ces composantes. Dans ce sens, je considère que le « Big Data » n’apporte pas en soi de nouveauté dans les concepts de traitement de données, mais plutôt dans leur implémentation permettant de répondre à de nouvelles contraintes.
Vers une approche distribuée et « simplifiée »
Nous avons vu que les défauts des technologies actuelles face aux problématiques du Big Data sont liées à leur rigueur dans le format des données (« Variété ») et à la non-_scalabilité_ des outils (« Volume » et « Vélocité »).
Pour répondre à ces problématiques, les solutions Big Data sont hautement distribuées afin de répartir les traitements sur un cluster de machines travaillant de concert. Cette approche distribuée permet de répondre « simplement » aux besoins de scalabilité du Big Data puisqu’il suffit de cumuler un ensemble de machines modestes jusqu’à atteindre les performances voulues, et d’en rajouter si les besoins augmentent, au lieu de modifier des machines existantes.
Par ailleurs, pour répondre à la problématique de variété, l’approche Big Data est « simplifiée » dans le sens où elle est plus souple que les outils traditionnels tels que les systèmes de gestion de bases de données relationnelles (SGBDR). Par exemple, la plupart des solutions Big Data permettant la lecture de données tabulaires appliquent le schéma à la lecture (schema-on-read) : c’est lors de la lecture des données qu’on fait correspondre les données à un schéma de table ; à l’opposé des SGBDR fonctionnant en schéma à l’écriture : le schéma est appliqué aux données lors de l’écriture et les données sont enregistrées selon ce schéma.
Suivant le même principe de souplesse et de simplicité, la grande majorité des solutions de Big Data laissent à l’utilisateur le soin de gérer le format de stockage des données, pouvant être un format brut type CSV ou un format sérialisé et/ou compressé comme le Parquet ; à l’opposé de la majorité des outils classiques tels les SGBDR qui gèrent elles même le stockage.
Hadoop
Quelques recherches permettent de se rendre rapidement compte qu’Hadoop est la base de l’écosystème de technologies du Big Data.
Inspiré des publications de Google sur GoogleFS et MapReduce, Hadoop est un framework en Java servant de socle à la plupart des technologies de Big Data. Ce framework est constitué de deux éléments principaux :
- Hadoop File System (HDFS) : un système de fichier distribué permettant de stocker des fichiers sur le cluster de machines comme s’il s’agissait d’un seul disque.
- Hadoop MapReduce : une implémentation du paradigme MapReduce permettant par héritage d’écrire simplement des traitements distribués sur les données stockées dans HDFS.
La quasi-totalité des technologies de Big Data utilisent HDFS, et une grande partie utilise également MapReduce.
Résumé des technologies Big Data
L’ensemble de ces technologies, plus ou moins interdépendantes et complémentaires, constituent un « écosystème Hadoop » énorme, que je vais présenter rapidement.
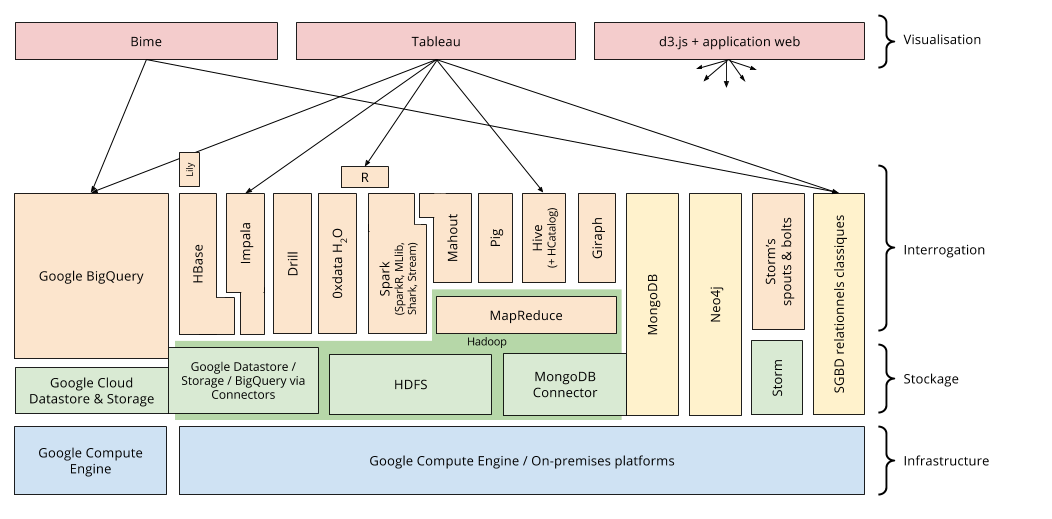
La figure ci dessus présente le schéma récapitulatif décrivant les dépendances des différentes technologies. On y distingue plusieurs couches :
- l’infrastructure c’est-à-dire les machines, pouvant être « on-premise » donc gérées soi-même localement, ou louées et hébergées dans le cloud ;
- le stockage qui peut être HDFS ou d’autres systèmes de fichiers distribués offrant les mêmes interfaces ;
- l’interrogation / analyse par diverses solutions se basant pour certaines sur MapReduce ;
- la visualisation des résultats.
Sans aller dans le détail, parmi ces technologies, on retrouve des solutions :
- de traitement de données dont le traitement peut être écrit dans un langage de programmation classique (MapReduce, Spark…) ou via un langage de script dédié (Pig…)
- de bases de données NoSQL orientés document, graphes, colonnes ou clé-valeur (MongoDB, Giraph, Neo4j, HBase, HCatalog…)
- d’interrogation de données en pseudo-SQL transformant la requête en traitement distribués sur des fichiers de données distribués (Hive, Impala, BigQuery, Drill, Spark SQL…)
- de Machine Learning (Mahout, 0xdata H2O, Spark MLlib…)
- de traitement de flux de données en temps réel (Storm, Spark Streaming…)
Cette liste est loin d’être exhaustive mais donne une bonne idées générale des différentes solutions.
Distributions Hadoop
Il n’est pas rare d’avoir besoin d’un ensemble d’outils de cet écosystème, et les dépendances et incompatibilités n’étant pas toujours simple à gérer, des entreprises fournissent des « distributions Hadoop », c’est-à-dire un écosystème Hadoop pré-packagé et préconfiguré permettant de ne pas avoir à se soucier de ce travail d’installation, de configuration, de résolution de dépendances et d’incompatibilités entre les composants, pouvant s’avérer très pénible quand on est pas un expert.
Les principales distributions Hadoop sont celles de Cloudera, HortonWorks et MapR.
Evolution du Big Data : le développement de Spark et la fin de MapReduce
Chaque technologie de l’écosystème Big Data a son usage, ses avantages et ses inconvénients. Le milieu du Big Data étant en explosion et qui plus est un domaine où on cherche toujours à améliorer les performances des outils, le paysage technologique bouge très vite, et de nouvelles solutions naissent très régulièrement, avec pour objectif d’améliorer les technologies existantes.
Je pense que les meilleurs exemples pour illustrer cette évolution sont MapReduce et Spark.
MapReduce est un pattern décrit par Google en 2004, implémenté peu de temps après dans le projet Nutch de Yahoo qui deviendra le projet Apache Hadoop en 2008. Autant dire qu’à l’échelle du Big Data, MapReduce est un dinosaure. C’est un algorithme qui a l’avantage de supporter très bien d’énormes volumes de données, mais qui présente cependant des lenteurs, particulièrement visibles sur des volumes modestes.
Ces lenteurs de MapReduce font qu’il commence à être abandonné par les solutions voulant proposer des traitements quasi-instantanés sur les volumes modestes. Pour l’anecdote, Google a annoncé lors de la Google I/O 2014 que le paradigme MapReduce a déjà eu deux successeurs en interne, dont le dernier vient d’être proposé en solution SaaS sous le nom Google Cloud Dataflow.
On peut ainsi constater que toutes les solutions se voulant rapide n’utilisent pas MapReduce mais interrogent directement le système HDFS. La solution la plus emblématique est Spark, un outil qui permet d’écrire des applications distribués très simplement et qui propose des bibliothèques de traitement classique, mais également d’interrogation en SQL, de Machine Learning, de graphes, et de traitement en temps réel ; et qui peut travailler indifféremment sur des données sur disque ou en chargées en RAM pour de bien meilleures performances.
Bien qu’encore jeune, Spark possède une communauté énorme et est un des projets Apache qui se développe le plus vite. Cette solution s’annonce un peu comme le successeur de MapReduce d’autant qu’il a l’avantage de centraliser une grande partie des outils nécessaires dans un cluster Hadoop.
Hadoop dans le cloud
Comme nous l’avons vu, il y a deux types d’infrastructures possibles pour supporter un cluster Hadoop : une infrastructure « on-premise » où les machines sont achetées, hébergées et gérées soi-même ; ou une infrastructure gérée dans le cloud type Infrastructure as a Service (IaaS) où on se contente de louer des machines sans se soucier de la gestion. Voyons plus en détail ce second cas.
Pour faire du Big Data hébergé, il est possible de louer des serveurs chez des hébergeurs classiques (OVH, 1&1, Netissime, etc.) qui louent des serveurs « standard » au mois. Cette approche est finalement identique à l’approche on-premise sauf que l’on a pas besoin de gérer les machines. Cela ne correspond pas selon moi à l’approche cloud.
La « vraie » approche cloud passe par des hébergeurs spécialisés (Amazon et Google en particulier) qui proposent un panel de services destinés au traitement scalable de données et proposant la location de machines virtuelles à l’heure ou à la minute. Ces offres proposent un ensemble de services poussant en particulier à séparer le stockage qui est facturé au volume (Amazon S3, Google Cloud Storage) du cluster de traitement facturé au temps de traitement (Amazon Elastic Compute Cloud (EC2), Google Compute Engine). Ainsi, alors que le stockage est persistant, le cluster de traitement est lui éphémère et permet ainsi de provisionner dynamiquement le nombre de machines nécessaires pour l’exécution d’un traitement puis de les dé-provisionner.
Cette nouvelle approche, bien plus souple permet de faire des économies importantes si le cluster a une charge très variable. Ainsi, MapR (fournisseur de distribution Hadoop) a fait la démonstration du déploiement d’un cluster de 2103 machines pour trier 1,5 To de données en 1 minute pour un coût de 20$.
C’est une approche assez disruptive du modèle classique puisqu’il est nécessaire de prévoir des mécanismes de provisionnement et de configuration automatisés des machines, mais permet de profiter d’une souplesse exceptionnelle en capacité de traitement, inatteignable sur un modèle classique.
Il est important de noter qu’Amazon s’est emparé de ce marché depuis plusieurs années, lançant par exemple Amazon EC2 en 2006 et Amazon Elastic MapReduce en 2009, et est actuellement en monopole sur les services de cloud Big Data. En comparaison, Google n’a lancé Google Compute Engine qu’en 2012. Amazon a donc une large avance commerciale dans le domaine, alors que Google, qui dispose pour ses besoins internes de technologies d’hébergement et de Big Data de pointe, commence à peine à les ouvrir au public. Il semble cependant que ce soit la direction que prend Google, qui rend petit à petit accessible au public des outils Big Data très intéressants et innovants utilisant des technologies internes comme BigQuery (interrogation de données très rapide en SQL) ou Google Cloud Dataflow (successeur interne à MapReduce).