LogAnalysis : Outil Web Open-Source De Business Intelligence Gégraphique
Contexte
En ASI (Architecture des Systèmes d’Information), à l’INSA de Rouen, le second semestre de 4ème année et le premier semestre de 5ème année sont l’occasion pour les étudiants de travailler sur un Projet INSA Certifié (PIC), un projet industriel type R&D commandé par une entreprise et réalisé par les étudiants.
5 sujets sont réalisés par 6 équipes de 7 à 9 étudiants durant 1 an scolaire à raison de 25 à 28h par semaine et par personne. Pour être exact, une des équipes n’existe que pendant le premier semestre de PIC et joue le rôle de sous-traitant pour une autre équipe. Cette équipe disparaît au second semestre de PIC pour permettre aux étudiants de partir à l’étranger.
Sujet
Le sujet sur lequel mon équipe à travaillé consiste à développer un outil open-source permettant de faire de Business Intelligence géographique, et surtout, de la rendre naturelle à l’utilisateur, accessible sans connaissance de la théorie de la « GeoBI ».
Ce sujet nous a été proposé par le Centre de Recherche Publique Henri Tudor, basé au Luxembourg, maintenant nommé Luxembourg Institute for Science and Technology (LIST). L’équipe sous-traitante a travaillé avec nous sur ce sujet.
La Business Intelligence
En très résumé, la Business Intelligence (BI) ou informatique décisionnelle, c’est le fait de pouvoir analyser des grandes quantités de données généralement structurées selon un grand nombre de dimensions. Par exemple, le chiffre d’affaire en fonction des dimensions temps, espace, client, secteur d’activité, produit, etc.
La Business Intelligence à pour but de permettre d’analyser ces masses de données structurées afin d’en faire émerger une décision éclairée.
On peut décomposer la Business Intelligence entre 3 grandes étapes :
- Collecte des données afin de constituer une base de données structurées
- Sélection et traitement des données
- Affichage des données à l’utilisateur
Collecte des données
Cette étape préliminaire à la Business Intelligence n’est pas traitée dans le cadre du PIC car elle est spécifique à chaque entité désirant faire de la Business Intelligence. Son but est de collecter les données venant de multiples sources afin de constituer une base de données la plus précis et complète possible. Ces données sont alors stockées dans des data warehouses et datamarts. Cela constitue alors des bases de données OLAP.
Sélection et traitement des données
La première étape d’une analyse de BI est la sélection des données intéressantes à l’étude que l’utilisateur veut mener (ex : sélection des données de la France en 2014 uniquement). C’est le slice OLAP.
Le traitement de données le plus courant est ensuite de choisir comment agréger les données afin d’en obtenir des résultats pertinents (ex : agrégation par mois et par département). C’est le dice OLAP.
C’est – de façon réductrice bien sûr – le principe de l’OLAP : limiter le champ de données et l’agréger aux niveaux les plus pertinents.

Affichage des données
La deuxième étape d’une analyse de BI est l’affichage des données à l’utilisateur. L’affichage le plus simple est l’affichage d’un tableau. Ce n’est cependant pas la façon la plus simple pour réussir à interpréter les données. On introduit alors des graphiques, des cartes choroplèthes, etc.
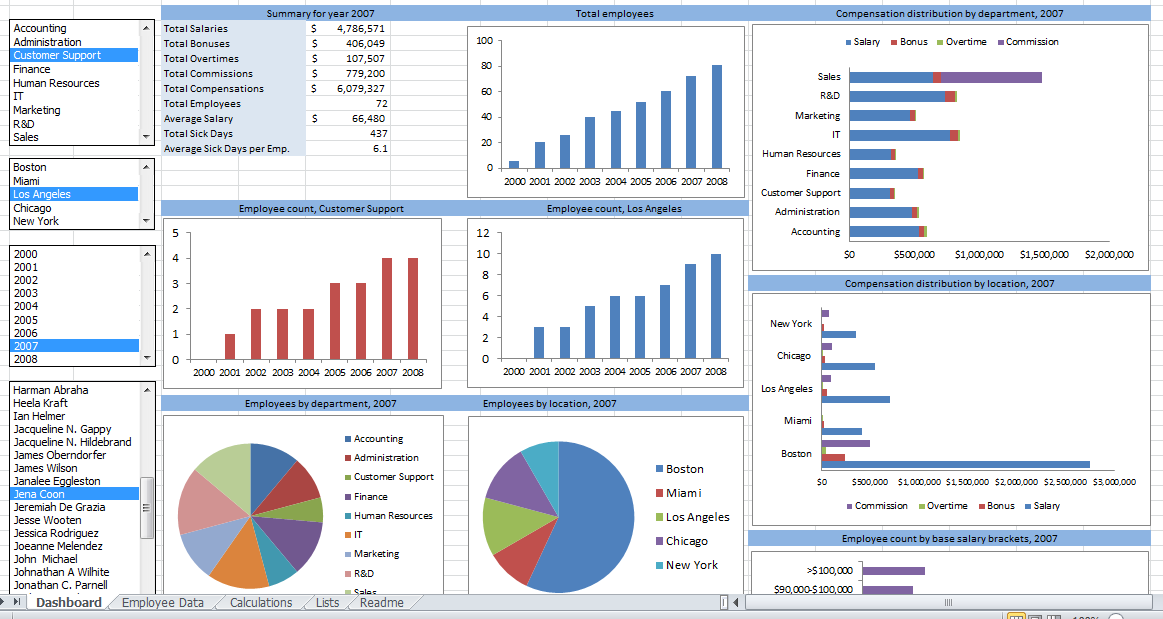
Objectifs du projet & démonstration
Ce projet avait donc pour but de développer une interface web permettant de réaliser des analyses de BI géographique en s’intégrant à GeoNode, plateforme qui offre déjà des outils de gestion de données géographiques. Le tout a été développé sous licence Open Source (GPLv3) est est disponible sur GitHub.
Les objectifs du projets étaient les suivants :
- Traitement et récupération des données depuis la base de données OLAP GeoMondrian
- Affichage des résultats sous la forme de divers graphiques : carte choroplèthe, diagramme en secteur (pie chart), en barres (bar chart), à bulles (bubble chart), tableau, nuage de mots (word cloud)
- Interaction avec les graphiques permettant a l’utilisateur d’interroger la base de données OLAP et de réaliser son analyse de BI de façon intuitive et naturelle :
- Filtrage dynamique (slice OLAP) au clic ;
- Zoom dimensionnel (drill-down et roll-up OLAP modifiant donc à la fois le slice et le dice) au zoom molette. Par exemple, un drill-down sur la France affichera les régions de France. Différentes version du drill-down sont possible : simple (sur 1 élément), multiple (plusieurs éléments), partiel (drill-down sur un élément tout en conservant les éléments du niveau supérieur permettant de comparer des données de différents niveaux, par exemples les régions de France et les autres pays d’Europe)
Voici une démonstration rapide de l’application permettant d’avoir un aperçu rapide des objectifs :
Architecture
Architecture globale
Le diagramme ci-dessous décrit l’architecture globale de la solution développée :
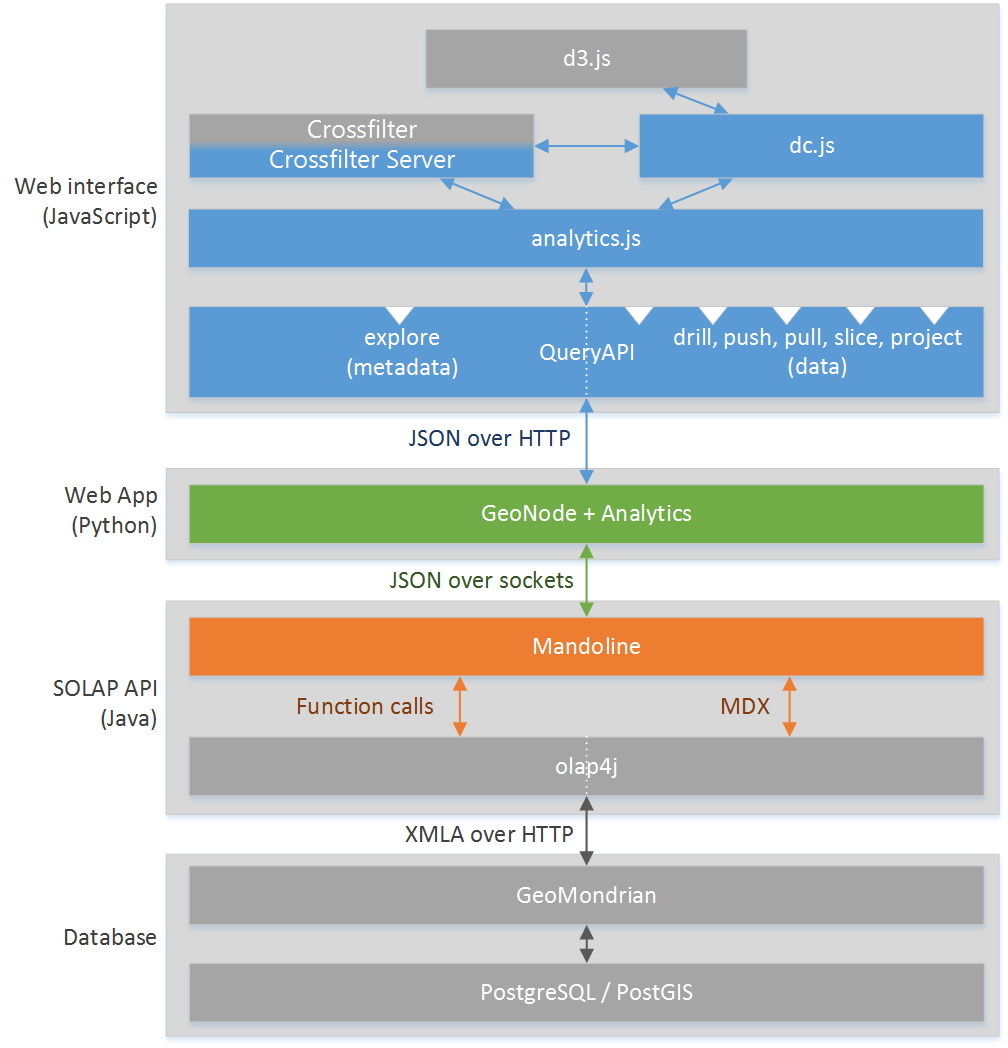
On y retrouve 4 composants :
- L’interface web permettant la visualisation des données. Elle se compose de plusieurs éléments :
- analytics.js, le package développé pour gérer l’interface
- QueryAPI, un proxy des interfaces de Mandoline, l’API SOLAP
- crossfilter, une sorte de petit serveur OLAP côté client
- crossfilter server, une librairie développée pour permettre de réaliser les mêmes operations que crossfilter, mais déléguant les calculs OLAP au serveur via une API
- d3.js, une librairie utilisée pour les rendus SVG
- dc.js, une version modifiée du dc.js original pour réaliser des rendus de graphiques interactifs de données dimensionnelles
- Une application web en Python, analytics, délivrant l’interface web, étendant l’application web existante GeoNode
- Une API SOLAP en Java nommée Mandoline, et sa dépendance olap4j, nous permettant d’interroger GeoMondrian simplement en JSON
- La base de données OLAP avec le serveur SOLAP GeoMondrian récupérant les données depuis une base PostgreSQL, réalisant le traitement des données
analytics.js
Le package analytics.js représente la majeure partie du travail réalisé sur ce projet. Il est composé de divers « namespaces », chacun contenant diverses et « classes », ces appellation étant utilisé pour la compréhension du propos puisqu’étant en JavaScript, ces types d’éléments n’existent pas et sont dans notre cas des objets.
Voici l’architecture du package :
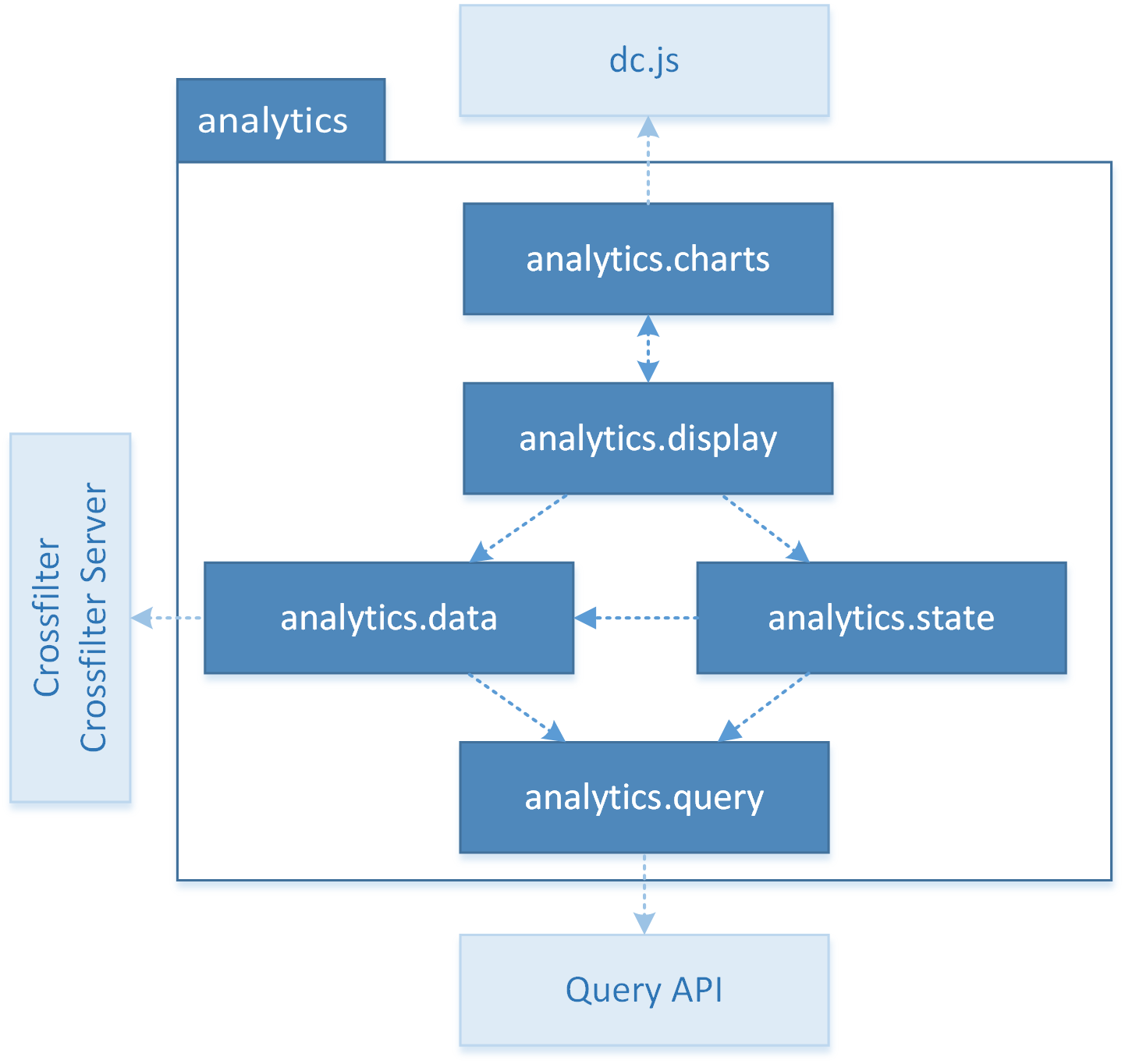
On y trouve les namespaces :
- analytics.query qui simplifie l’interrogation de l’API SOLAP via QueryAPI en offrant des fonctions spécialisées
- analytics.data qui offre des types de données permettant de représenter les éléments OLAP, et qui stocke les données reçues
- analytics.state qui stocke et offre des fonctions permettant de modifier l’état OLAP de l’analyse en cours (pour simplifier, quels éléments de quels niveaux sont en cours d’étude)
- analytics.display gère l’interface (où est chaque graphique et qu’affiche-t-il) et les interactions avec celle-ci
- analytics.charts offre des classes pour chaque type de graphique qui peuvent être instanciées pour chaque nouveau graphique
Cross-filtering and crossfilter-server.js
Une des problématiques majeures du projet est de fournir un filtrage croisé efficace sur l’interface. On peut voir cette fonctionnalité dans la vidéo de démonstration. En effet, ce filtrage est très pratique pour l’utilisateur car elle lui permet de voir simplement comment les données se distribuent parmi les divers éléments d’une dimension et d’explorer le cube OLAP.
Cette fonction de filtrage est donc fortement sollicitée et se doit d’être particulièrement efficace tout en supportant de fort volumes de données.
Il y a en fait deux solutions permettant de mettre en oeuvre cette fonctionnalité, représentées sur ce schéma :
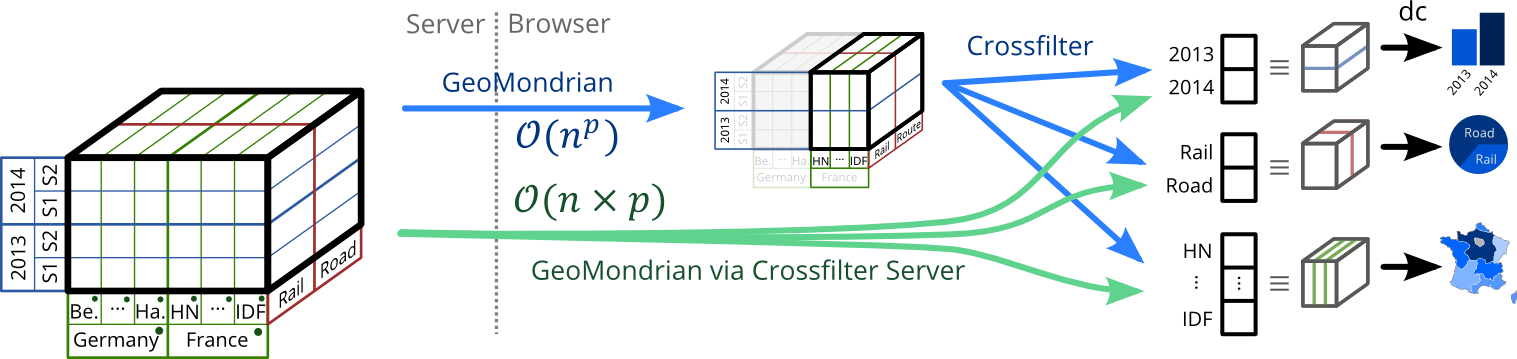
On voit sur ce graphique le cube OLAP à gauche qui stocke les données, et à droite des graphiques que l’utilisateur veut visualiser.
Première solution : Crossfilter
La première possibilité est de demander au serveur OLAP, GeoMondrian, de calculer un cube de données plus petit contenant ce que l’on est en train d’étudier. Sur le diagramme, ce cube intermédiaire est situé au centre et contient les données par région de France, années et mode de transport.
Ce cube temporaire est téléchargé dans le navigateur de l’utilisateur et fourni a crossfilter. Crossfilter pourra ensuite calculer les projections de ce cube sur chaque dimension, et ces projections seront utilisées par dc.js pour réaliser les rendus.
Dans cette solution, l’interface sera très réactive au filtrage, car crossfilter possède déjà toutes les données dont il a besoin pour calculer les projections en tenant compte des filtres, et pourra réaliser les calculs en moins d’une seconde.
Cependant, le défaut de cette solution est le nombre de valeurs dans le cube, qui est le produit du nombre d’éléments étudiés dans chaque dimension (par exemple pour 6 régions, 2 ans et 3 modes de transport on a 6 × 2 × 3 = 36 valeurs), et cette taille augmente donc exponentiellement. On ne pourra donc supporter que des volumes raisonnables car le cube finira par devenir trop lourd pour être téléchargé en un temps raisonnable.
Seconde solution : Crossfilter Server
L’alternative consiste à demander à GeoMondiran de calculer directement les projections du cube OLAP, après filtrage, sur chaque dimension étudiée sans calculer le cube temporaire.
Dans ce cas, la taille des données chargés est la somme du nombre d’éléments étudiés dans chaque dimension (par exemple pour 6 régions, 2 ans et 3 modes de transport on a 6 + 2 + 3 = 11 valeurs), et cette taille augmente linéairement. On sera donc capable de supporter des volumes importants car on charge bien moins de données (tant que GeoMondrian supporte ces volumes bien sûr).
Cependant, l’inconvenient de cette solution est que quand l’utilisateur change de filtres, on doit demander à nouveau à GeoMondrian les projections sur chaque dimension en prenant en compte les nouveaux filtres. Cela ralenti donc le temps de réaction lors du filtrage car on doit interroger le serveur là ou crossfilter faisait les calculs localement.
Un autre problème de cette solution est que notre librairie d’affichage, dc.js, est dépendante de crossfilter en tant que modèle de données, on ne peut pas lui donner directement des données.
Pour répondre à ce problème et rendre cette alternative possible, nous avons développé une petite librairie nommée Crossfilter Server. Cette librairie a presque les même interfaces d’I/O que Crossfilter (seule l’initialisation change). Crossfilter Server va donc reproduire le fonctionnement de Crossfilter sans posséder les données (le cube intermédiaire), il va déléguer les calculs à une API qui va, dans notre cas, interroger GeoMondrian.
Ainsi, nous pouvons utiliser dc.js indifféremment avec Crossfilter ou Crossfilter Server.
Récapitulatif & solution
Pour résumé, nous avons 2 solutions :
Crossfilter
-
Volumes raisonnables - Filtrage & agrégats côté client rapide (< 10 ms)
Excellente réactivité
Crossfilter Server
-
Volumes importants - Filtrage & agrégats côté serveur, rechargement (≈≈\approx 1s)
Réactivité réduite
Notre solution définitive consiste a utiliser ces deux solutions, en utilisant l’une ou l’autre selon le volume de données en cours d’étude, en passant dynamiquement de l’une à l’autre selon les besoin.
Conclusion
Cet article est bien sûr un résumé rapide d’un projet conséquent. Si vous voulez davantage d’informations, vous pouvez consulter l documentation du projet disponible sur le wiki du dépôt GitHub ou jeter un oeil au code des composants listés précédemment. Si vous voulez, vous pouvez même contribuer à ce projet en faisant une pull-request !